
4DIdentity - Teil 1
In dieser Blogpost-Serie möchten wir dir einen Einblick geben, wie wir unsere Anwendungen entwickeln und warten. Kürzlich haben wir einen internen Dienst namens 4DIdentity entwickelt. Dieser Dienst fungiert als unser zentraler Identitätsanbieter für intern genutzte Tools wie ArgoCD und HashiCorp Vault. Wir planen auch, ihn in unseren zukünftigen Managed-Service-Angeboten einzusetzen, also bleib gespannt!
Bei der Entwicklung des 4DIdentity-Dienstes haben wir uns an bewährten Praktiken orientiert. Als Ergebnis wird der Dienst vollständig durch Infrastructure as Code (IaC) verwaltet, in allen Phasen über GitLab-Pipelines bereitgestellt und basiert vollständig auf serverloser Infrastruktur. Dadurch ist er einfach zu warten, kostengünstig und hochgradig widerstandsfähig.
Heute starten wir die Blogpost-Serie, indem wir über unsere Motivation und den Anwendungsfall unseres neuen internen Dienstes sprechen. Als Nächstes geben wir einen Überblick über die serverlose Architektur, einschliesslich unserer Überlegungen zur Notfallwiederherstellungsstrategie. Abschliessend werfen wir einen Blick auf unser Monitoring-Setup für die Dienste, auf denen unsere Lösung basiert.
Anwendungsfall
Die Motivation, unseren eigenen internen IdP zu entwickeln, liegt hauptsächlich in unseren Bestrebungen, Managed Services für unsere Kunden aufzubauen. Diese Managed Services werden Komponenten enthalten, bei denen entweder wir oder unsere Kunden sich einloggen müssen. Da die meisten unserer Kunden wahrscheinlich bereits eigene Identitätslösungen haben, müssen wir unabhängig bleiben, um auf die Komponenten zugreifen zu können, für die wir verantwortlich sind.
Daher haben wir uns entschieden, einen eigenen Identitätsverwaltungsdienst zu entwickeln, der sich nahtlos in die für unsere Managed Services genutzten Anwendungen integrieren und bestehende Identitätsanbieter nutzen kann.
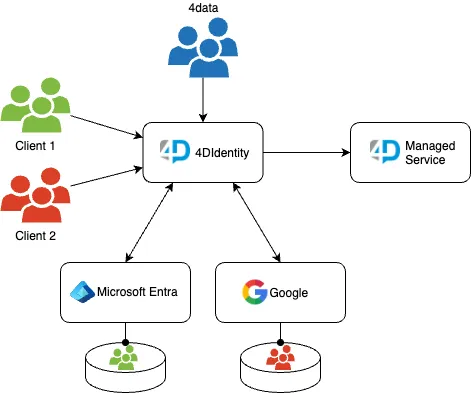
Architektur
Das Ziel von 4DIdentity ist es, einen zentralen Identitätsanbieter (IdP) bereitzustellen, der zuverlässig, sicher und einfach zu warten ist. Wir haben uns für Amazon Cognito entschieden, da es serverlos ist und vollständig mit Infrastructure as Code (IaC) verwaltet werden kann. Ein zusätzlicher Vorteil von AWS ist die nutzerbasierte Preisgestaltung, die es uns ermöglicht, die Anwendung kostengünstig zu betreiben. Gleichzeitig erfüllt es unsere Anforderungen an hohe Verfügbarkeit und Service-Wiederherstellungsstrategie.
Zusätzlich nutzen wir die Benutzerpool-Funktion des Cognito-Dienstes. Benutzerpools bieten verschiedene Identitätsmanagement-Funktionen wie Anmeldung, Registrierung und Identitätsföderation mit externen IdPs.
Amazon Cognito integriert sich mit mehreren anderen AWS-Diensten wie CloudFront, Route 53, Simple Email Service (SES), Certificate Manager (ACM) und Web Application Firewall (WAF). Das folgende Bild zeigt eine vereinfachte Architekturübersicht der 4DIdentity-Komponenten.
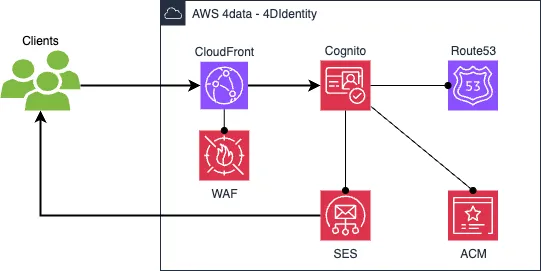
Es sieht so aus, als müsstest du viele verschiedene Dienste konfigurieren, aber tatsächlich werden die meisten davon automatisch vom Cognito-Dienst konfiguriert. Abhängig vom Anwendungsfall benötigst du möglicherweise nur einen Teil der Dienste. Wenn du beispielsweise eine von AWS bereitgestellte Domain verwendest, benötigst du den ACM-Dienst nicht und alle Route 53-Konfigurationen werden vom Cognito-Dienst übernommen.
Hohe Verfügbarkeit sicherstellen
An dieser Stelle möchten wir uns auf einige wichtige Verfügbarkeitsaspekte konzentrieren, die wir für den 4DIdentity-Dienst gewählt haben, da sie die Architektur beeinflussen. Im Falle einer Katastrophe verlassen wir uns auf die Pilot Light strategy vorgeschlagen von AWS: Alle erforderlichen Komponenten werden in einer primären und einer ruhenden sekundären Region bereitgestellt und konfiguriert.
Diese Strategie hat folgende Vorteile:
- Der Failover-Standort ist sofort einsatzbereit, was die Anzahl der Aktivitäten erheblich minimiert und somit das Risiko von Fehlern bei der Wiederherstellung des Dienstes unter Druck reduziert.
- Durch die Nutzung von IaC wird der Aufwand zur Bereitstellung einer Kopie der erforderlichen Komponenten in der Failover-Region reduziert.
- Da die gesamte Lösung serverlos ist und wir nur nach Nutzung bezahlen, sind die Kosten für die Failover-Bereitstellung minimal.
Allerdings hat die Strategie auch ihre Herausforderungen:
- Da Benutzerpools auf gemeinsam genutzte/globale Dienste wie Route 53 oder SES angewiesen sind, muss der Bereitstellungsprozess und die Regionalkompatibilität (insbesondere in Bezug auf SES) sorgfältig analysiert und angepasst werden.
- Die Bereitstellung der Dienste in mehreren Regionen erfordert auch eine ordnungsgemässe Überwachung in all diesen Regionen.
Das folgende Bild zeigt die Architektur des 4DIdentity-Dienstes unter Verwendung der Pilot Light DR-Strategie.
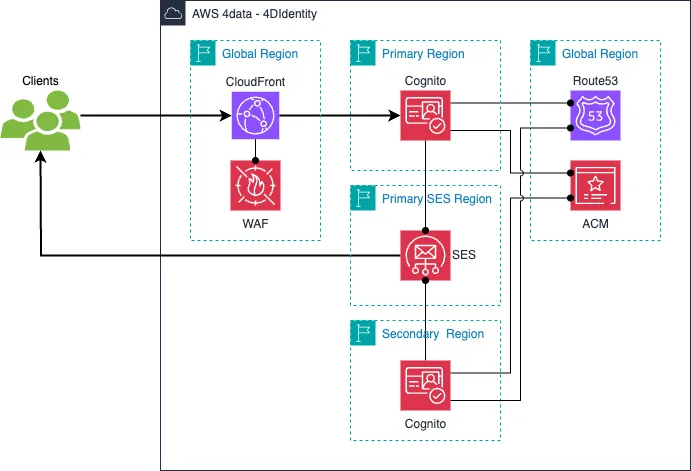
Ein paar Dinge zu beachten:
- Wenn du eine benutzerdefinierte Domain für deinen Cognito-Benutzerpool verwendest, müssen die primären und sekundären Benutzerpools separate Domains konfiguriert haben, da Route 53 ein globaler Dienst ist.
- SES- und Cognito-Regionen können nur wie von AWS vordefiniert kombiniert werden. Daher haben wir uns entschieden, SES in einer Region bereitzustellen, die von Benutzerpools in den primären und sekundären Regionen genutzt werden kann. Dies ermöglicht es uns auch, den SES-Dienst im Falle eines Problems in seiner primären Region zu failovern.
Überwachung
Obwohl wir ausschliesslich auf serverlose Dienste von AWS setzen, möchten wir diese Dienste dennoch überwachen und benachrichtigt werden, wenn einer der Dienste ausfällt oder beeinträchtigt ist. Amazon EventBridge übernimmt diese Aufgabe und läuft ebenfalls als serverloser Dienst.
Amazon EventBridge ermöglicht es dir, Regeln zu konfigurieren, die alle AWS Health-Ereignisse für alle von 4DIdentity genutzten Dienste melden. Da diese Regeln regionale Ressourcen sind, müssen sie in den spezifischen Regionen bereitgestellt werden, die wir überwachen möchten. Die Regeln sind so konfiguriert, dass sie die Ereignisse an den zentralen Ereignisbus in unserem Cloud-Management-Konto senden. Vom zentralen Ereignisbus werden die Health-Ereignisse an SNS-Themen weitergeleitet, wo ein AWS Chatbot sie aufnimmt und eine Nachricht an unseren Slack-Kanal sendet.
Das folgende Bild zeigt die oben beschriebene Architektur.
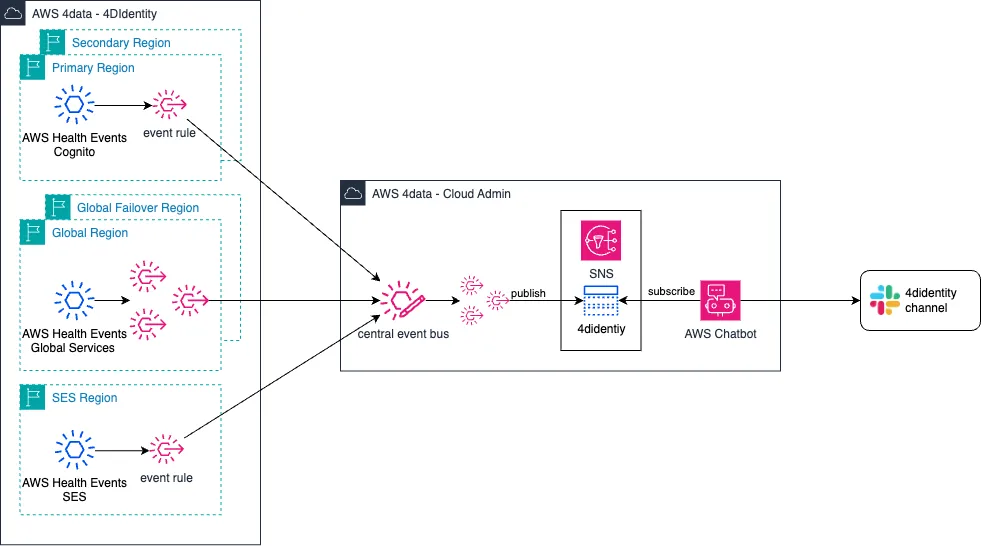
Noch einmal: Alle diese Dienste laufen serverlos, sind hochverfügbar und vollständig mit IaC wartbar. Zusätzlich kann es erweitert werden, indem zusätzliche Ereignisse von CloudWatch überwacht werden, falls erforderlich, z.B. Benachrichtigungen, wenn sich jemand über Cognito anmeldet oder wenn sich ein neuer Benutzer registriert.
Fazit
In diesem Beitrag haben wir die Designziele und die Architektur besprochen. Ausserdem haben wir skizziert, wie der Dienst im Falle einer Katastrophe wiederhergestellt wird und wie er überwacht wird.
Im zweiten Teil dieser Blogpost-Serie erklären wir, wie alle Infrastrukturkomponenten mit IaC und GitLab-Pipelines bereitgestellt werden, um die Einrichtung aller Umgebungen vollständig zu automatisieren, einschliesslich eines cleveren Tricks zur Verwaltung von temporären Umgebungen.
Bitte zögere nicht, uns für Feedback oder Fragen zu kontaktieren.

